前言
本文译自 https://bloggeek.me/webrtc-conferences-mix-or-route-audio/,仅节选,非全文。
混合 & 路由
WebRTC 中的群组通话可以采用不同的形式和以支持不同的规模。大多数情况下,WebRTC 多方通话有 2 种架构:混合(mixin) 和 路由(route)。
通常根据提供的功能,将媒体服务器分为 MCU 和 SFC,分别对应文中的混合和路由。
假设有 5 个人之间的对话。这些人中的每个人都可以说出自己的想法,其他人也可以听到他的讲话。如果所有这些人彼此远程,并且我们现在需要在 WebRTC 中对其进行建模,我们可能会将其视为如下图所示:
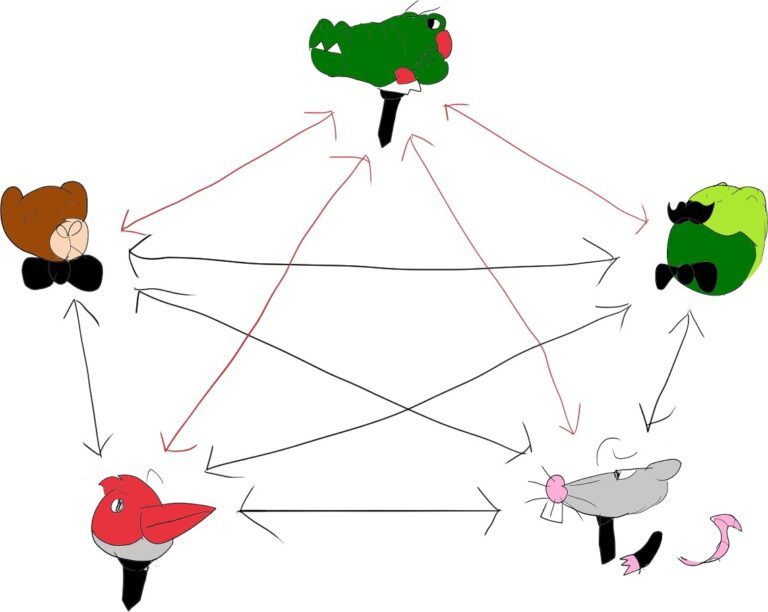
这种模式通常称为 Mesh,它对我们来说最大的缺点(尽管还有其他缺点)是它的混乱。参与者之间的连接数量随着用户数量呈多项式增长,我们需要分别向所有参与者发送相同的音频流。
WebRTC 规范主要介绍了使用ICE 技术建立P2P 的网络连接,即 Mesh 网络结构。
最直接的解决方案是让中央媒体服务器混合所有音频输入,减少所有网络流量和用户处理:
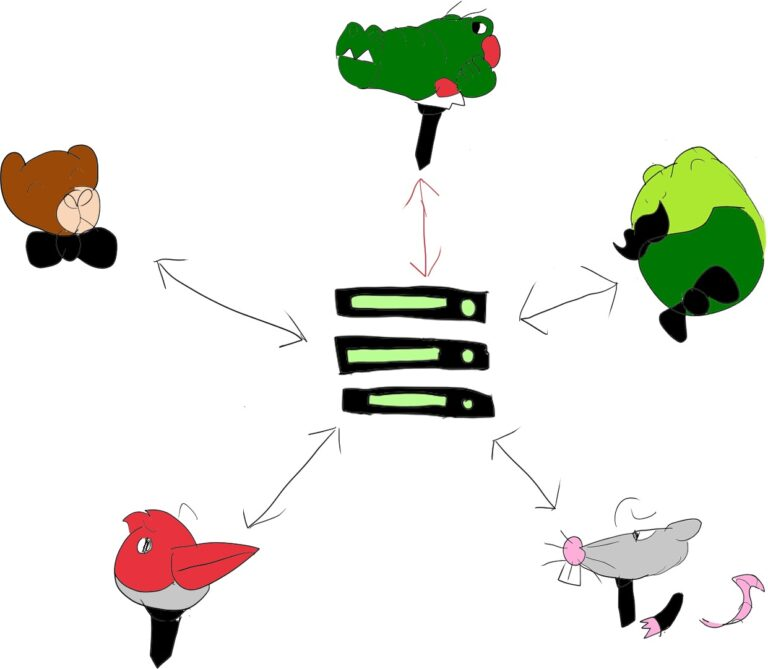
这种模式通常称为 MCU。这种模式下用户“感觉”好像他们只与单个实体/用户进行会话,并且由中央服务器负责所有令人头疼的问题。
对于服务提供商来说,这种方案可能有点昂贵,而且有时并不是最灵活的方法。这就是引入 SFU 路由模型的原因,尽管主要用于视频会议。
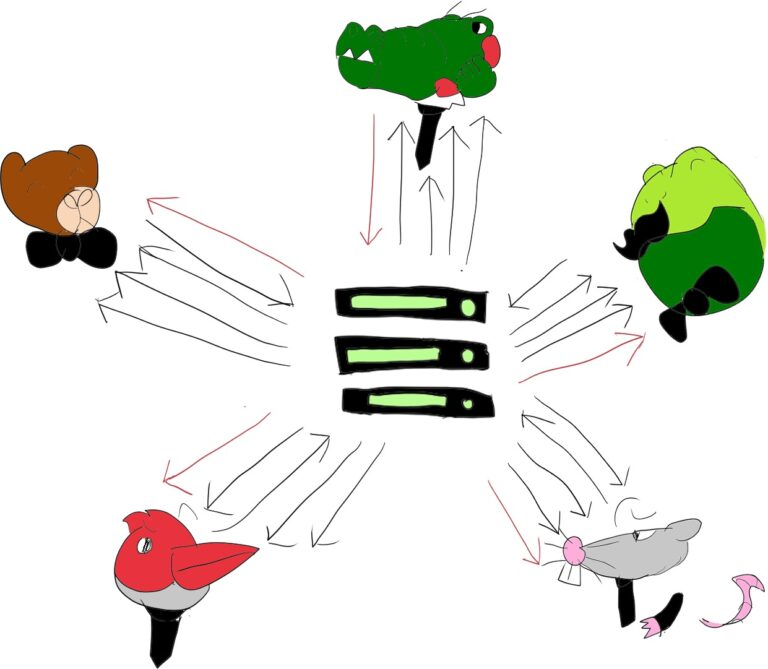
SFU 已经变得司空见惯,并且几乎在所有地方都是视频会议的首选架构模型。
虽然 SFU 在视频会议中很常用,但对于音频会议,应该使用哪种架构来处理?我们应该将其混合在媒体服务器中还是像处理视频一样将其路由?
在我继续尝试回答这个问题之前,我还想了解一件事,那就是我们今天可以用于 WebRTC 中的音频的一组媒体处理工具。
另外还有 Simulcast(联播),其对 SFU 进行了优化不小的优化,尤其对于视频会议来说很值得尝试。
音频处理技术
音频编码和解码是必须的、基础的事情。但除此之外,还有相当多的媒体处理和网络相关算法可以帮助应用程序达到所需的音频规模和质量。
在列出它们之前,以下是我收集所有这些内容时想到的一些想法:
- 该列表是动态的。随着新技术的引入,它每年都会发生一些变化。
- 您无法真正在所有用例中始终使用它们。您需要挑选与您的用例、用户和您所处的特定环境相关的选项。
- 我们现在也有一个基于机器学习的工具。我们肯定会在一两年内拥有更多这样的产品。
- 既然我们已经完成了高级 WebRTC 协议课程的所有课程的记录和发布,那么编译此列表就容易多了 – 我们已经非常详细地介绍了其中的大多数工具。
音频电平 (Audio Level)
音频电平是一种用于测量音频信号强度的技术。它可以用于判断是否存在音频,以及音频信号的强度。
有音频电平的 RTP 标头扩展,这允许 WebRTC 客户端指示在发送的编码音频数据包中可以找到的音频电平大小,然后接收器可以使用该信息而无需解码数据包。
人们可以用它做什么呢?
决定是否需要对数据包进行解码,或者如果没有或很少有语音活动或者音频电平太低(无论如何没有人会听到其中的内容),则将其丢弃。
您可以将其替换为 DTX(见下文),或者在 Last-N 架构中丢弃(不转发)数据包(见下文)。
同时应避免将其内容与其他音频通道混合(它没有足够的信息对任何人有用)。
间断传输 (DTX)
Discontinuous transmission (DTX) 是一种编解码器技术,它允许在没有语音活动的情况下停止发送数据包。
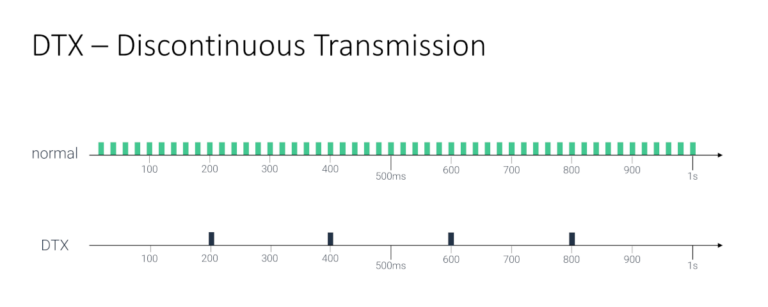
在大型会议中,大多数人都会倾听而不是互相争辩。因此,大多数音频流将只是静音。如果它们静音,则发送 DTX 而不是实际音频会减少网络流量。这对于最终处理更少数据包的 SFU 来说是一个福音。
在路由媒体时,SFU 媒体服务器还可以决定用 DTX 数据“替换”从用户接收的实际音频(因为用户的音频电平较低或由于他正在做出的 Last-N 决策)。
丢包隐藏 (PLC)
`Packet Loss Concealment (PLC)`` 是一种音频或视频通信中用于处理丢包(数据包丢失)的技术。当在网络通信中发生数据包丢失时,这可能会导致音频或视频的中断或断续。PLC 的目标是通过在丢失的数据包位置插入虚拟数据或采用其他补偿措施来减轻这种中断,以提供更平滑的音频或视频体验。
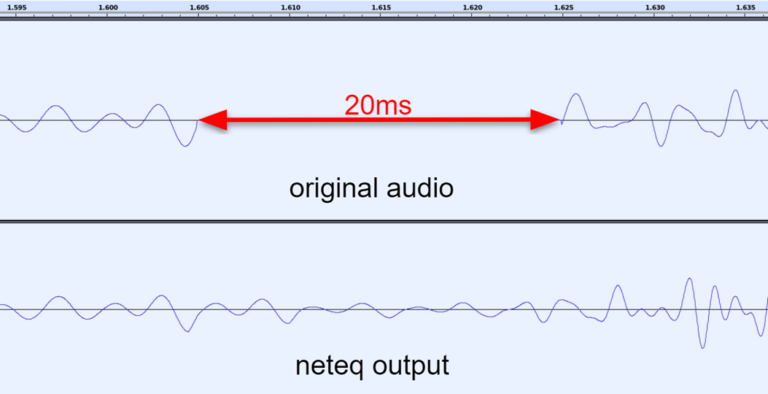
尽管数据包已丢失,但仍有一些内容需要向用户播放。您可以决定播放静音、重复上次听到的数据包、稍微降低音量等。
这可以在服务器端(特别是在 MCU 混音的情况下)或在客户端完成——此类算法已经在浏览器中实现。SFU 可以忽略这一点,主要是因为它们无论如何都不解码和处理实际媒体。
有时,这些可以使用机器学习来完成,例如谷歌专有的 WaveNetEq,它试图根据过去收到的数据包来估计和预测丢失的数据包中的内容。
丢包隐藏并不总是很好,但它是一种必要的罪恶。
RTX & NACK
Retransmission with Transmission Control (RTX)是一种丢包恢复技术,用于处理丢失的媒体数据包。它通过重新发送(重传)丢失的数据包来进行恢复。通常,当接收方检测到数据包丢失时,它会发送一个请求,请求发送方重新传输该数据包。
NACK(Negative Acknowledgment (NACK) 是一种通信协议中的一种反馈机制,用于指示接收方未成功接收到数据包。NACK 指示发送方重新发送丢失的数据包,从而实现丢包的恢复。
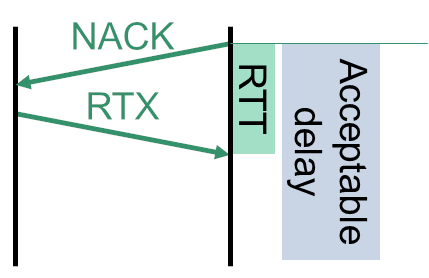
WebRTC 主要针对视频数据包执行此操作,但也可以应用于音频。
这曾经是一个被忽视的领域,因为上文提到的 PLC 技术和 Opus 内置的 FEC 技术。
目前,您可能会跳过这个工具,但如果对音频质量的优化非常感兴趣,则建议密切关注它。
RED & FEC
RED (REDundant coding) (冗余编码) 是 RFC 2198 中定义的 RTP 有效负载格式,用于编码冗余音频或视频数据。发送冗余数据的主要动机是能够恢复在有损网络条件下丢失的数据包。如果数据包丢失,则可以在接收器处根据后续数据包中到达的冗余数据来重建丢失的信息。
音频对带宽要求较低,因此适量的冗余数据不会对网络造成太大负担,尤其是在视频通话中。这种方法使我们能够以“低成本”获得更高的数据包丢失弹性。
这可以由客户端发送者实施,也可以从服务器端实施,以增强其接收到的内容 - 无论是作为 Mesh、MCU 还是 SFU。
FEC (Forward Error Correction) (前向纠错) 也是一种纠错技术,它内置于 Opus 中,同样是通过在原始数据包中添加冗余信息,使接收端能够根据收到的冗余信息自行修复丢失的数据包,而无需从发送端请求重传。
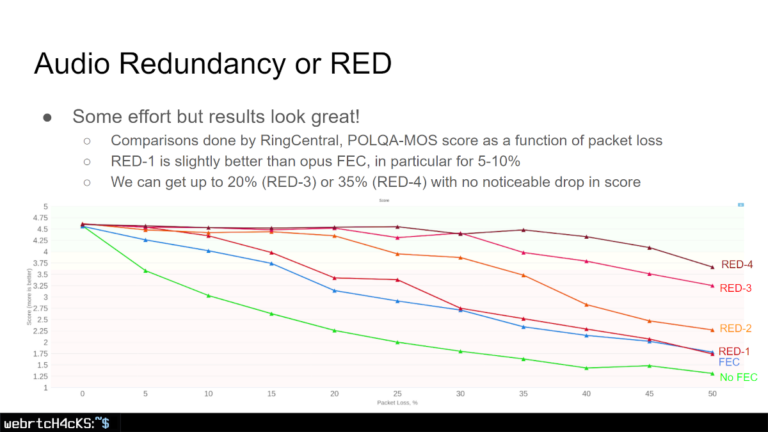
检查 Philipp Hancke 在 Kranky Geek 上关于高级音频编解码器的资料,然后还有何时复制以及复制多少的细微差别和令人头痛的问题,但这是另一篇文章的内容了。
Last-N
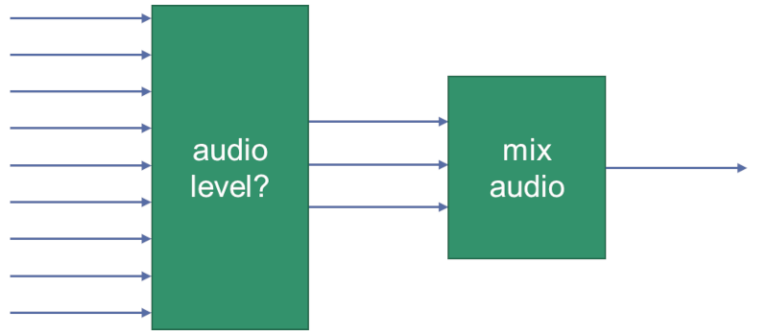
WebRTC 实现中的一个已知技术是,它在播放音频之前仅混合 3 个声音最大的传入音频通道。
为什么是3?我猜是因为 2 个还不够,而 4 个似乎没有必要。此外,混合的源越多,噪声水平就会越高,特别是在没有良好的噪声抑制的情况下(更多内容见下文)
嗯… 谷歌刚刚决定取消该限制。根据公告,这是因为音频解码在任何情况下都会发生,因此没有太多的性能优化来不混合它们。
所以现在,您可以决定是否要混合所有内容(以前无法混合),或者是否只想混合或路由一些最大音量(或最重要)的音频流(如果这就是您所追求的)。这会减少 CPU 和网络负载(取决于您使用的架构)。
例如,Google Meet 采用 Last-3 技术,最多仅向会议中的用户发送 3 个最大声的音频流。
哦!如果你想更深入地研究推理,2016 年有一篇很好的 Jitsi 论文解释了 Last N。
NS
NS 全称 Noise Suppression (噪声抑制),是一种用于消除噪声的技术。它可以在编码器中实现,也可以在解码器中实现。
如今,噪音抑制非常流行。RNNoise 是目前非常流行的基于 ML 的噪声抑制算法中的老手。
例如,Janus 已将其添加到他们的 AudioBridge 中,并实现了可选的 RNNoise 逻辑,以在 MCU 混音器中为每个传入流处理基于通道的噪声抑制。
谷歌在他们的 Google Meet 云中添加了这一点 —— 他们的 SFU 实现将音频传递到处理这种噪声抑制的专用服务器 —— 可能是通过解码、噪声抑制和编码回音频。
如今,许多供应商都在其客户端解决方案中引入了专有的噪声抑制技术。其中包括 Krisp、Dolby、Daily、Jitsi、Twilio 和 Agora,其中一些是通过合作伙伴关系,另一些是通过自我开发。
总结
混合让浏览器远离麻烦

为什么使用 MCU 来混合音频通话?因为它消除了浏览器的所有实施难题和细节。
为了了解它对服务器的一些影响,我建议您再次阅读 Lorenzo 的帖子。
这样做意味当用户增多时,需要投入更多服务器来解决问题。但是,至少在某种程度上,这可以很好地发挥作用,而无需考虑扩展、去中心化和其他花里胡哨的东西。
这也是多年来常用的做法。
需要注意的是,音频 MCU 需要生成相当多不同的输出流。对于 10 位参与者和 4 个发言者(Last-4 配置),情况如下:
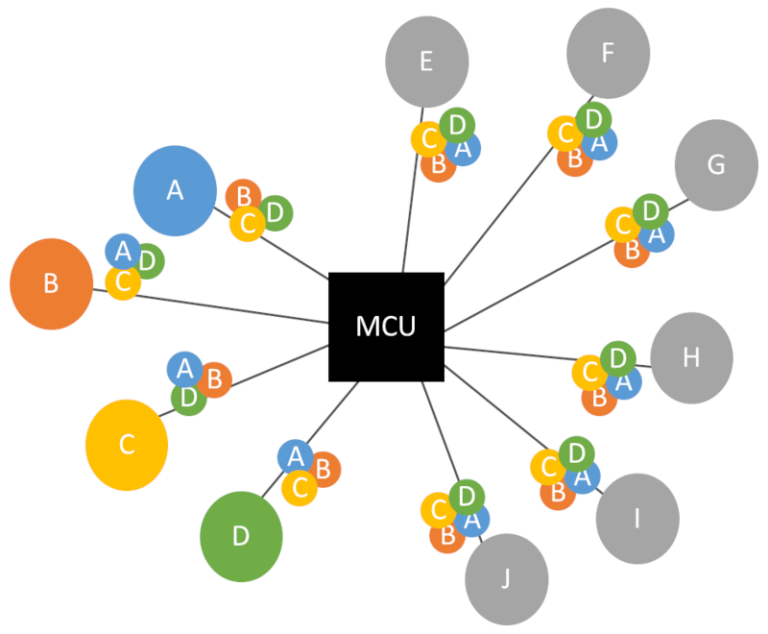
我们这里有 5 个独立的混音器:
- 1 混合所有 4 个有源扬声器
- 4 每次只混合 4 个中的 3 个 (我们不想让说话的人在流中混合自己的音频)
路由提供更好的灵活性
为什么我们使用 SFU 进行音频会议?因为我们已经将它用于视频… 或者因为我们相信这是当今做事的现代方式。
当谈到路由音频时,需要记住的是,我们在 SFU 和参与者之间保持着微妙的平衡,每个人都在这里发挥作用,以便在一天结束时获得更好的体验。
在许多方面,音频 SFU 比音频 MCU 更容易实现,但对其进行适当调整以从客户端实现中获得所有优势和优化是棘手的部分。